











Deep Insight Into
IT Technology & Trends
통찰력 있는 사람들이 함께하는 젊고 열정적인 IT 기업, 비젠메디컬.
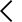 Back
Back벡터 임베딩 모델, BGE vs OpenAI vs Solar 어떤 걸 써야 할까?
벡터 임베딩 모델, BGE vs OpenAI vs Solar 어떤 걸 써야 할까? - "GPT-4를 붙였고, 벡터DB도 구축했고, 파인튜닝까지 했는데... 왜 한국어 문서 검색이

# 벡터 임베딩 모델, BGE vs OpenAI vs Solar 어떤 걸 써야 할까?
RAG 시스템의 정확도를 결정하는 임베딩 모델 완벽 비교 가이드 — 한국어 AI 서비스 구축자라면 반드시 읽어야 할 내용
---
🤔 RAG를 도입했는데 왜 엉뚱한 답변이 나올까? — 임베딩 모델이 범인이었습니다
"GPT-4를 붙였고, 벡터DB도 구축했고, 파인튜닝까지 했는데... 왜 한국어 문서 검색이 이렇게 엉망이지?"
AI 챗봇이나 기업용 RAG(Retrieval-Augmented Generation) 시스템을 구축해본 분이라면 한 번쯤 이런 좌절을 경험해봤을 겁니다. 수백만 원짜리 LLM을 붙여도, 정교하게 설계된 프롬프트를 써도, 정작 검색 단계에서 관련 없는 문서를 물어오면 최종 답변은 쓰레기가 되어버립니다. 쓰레기 입력 → 쓰레기 출력(Garbage In, Garbage Out)의 법칙은 AI 시대에도 변함없이 적용됩니다.
문제의 핵심은 놀랍게도 가장 기초적인 단계인 벡터 임베딩 모델 선택에 있는 경우가 대부분입니다. 어떤 임베딩 모델을 쓰느냐에 따라 동일한 질문에 대해 검색 정확도(Recall@10)가 60%대에서 90%대까지 천차만별로 달라집니다. 특히 한국어 문서를 다루는 서비스라면, 영어 중심으로 훈련된 글로벌 모델이 한국어의 형태소 구조, 조사 변화, 존댓말 체계를 제대로 이해하지 못해 치명적인 정확도 하락을 유발하기도 합니다.
실제로 국내 한 제조기업이 영어 중심 임베딩 모델로 사내 기술 문서 RAG 시스템을 구축했다가, 한국어 검색 정확도가 기대치의 절반 수준에 머물러 시스템 전면 교체를 결정한 사례가 있습니다. 반대로, 한국어에 특화된 임베딩 모델로 교체 후 Recall@10 기준 검색 정확도가 42% 향상되었다는 보고도 있습니다.
이 글에서는 현재 시장에서 가장 많이 사용되는 BGE-M3, OpenAI text-embedding-3, Solar Embedding, Cohere, Voyage AI 등 주요 임베딩 모델들을 철저하게 비교분석합니다. 단순한 벤치마크 점수 나열이 아니라, 실제 한국어 RAG 시스템 구축 시 어떤 모델을 어떤 상황에서 선택해야 하는지에 대한 실전 기준을 제시합니다. 비용, 속도, 라이센스, 다국어 지원까지 모든 축을 종합적으로 검토하겠습니다.

---
🧠 벡터 임베딩이란 무엇인가? — RAG 정확도의 진짜 출발점
벡터 임베딩(Vector Embedding)이란 텍스트, 이미지, 오디오 등 비정형 데이터를 고차원 수치 벡터로 변환하는 기술입니다. 쉽게 말하면, 사람이 이해하는 언어를 컴퓨터가 수학적으로 비교·연산할 수 있는 숫자 배열로 바꾸는 과정입니다.
예를 들어 "강아지"라는 단어는 768차원 혹은 1,536차원의 실수 벡터 `[0.23, -0.84, 0.12, ..., 0.67]`로 변환됩니다. 이때 "개"나 "반려동물"과 같은 의미적으로 유사한 단어는 벡터 공간에서 가까운 위치에 놓이게 됩니다. 이 "거리(Distance)"를 계산하는 것이 바로 RAG 시스템에서 관련 문서를 찾는 핵심 원리입니다.
RAG 시스템의 동작 흐름을 살펴보면 임베딩의 중요성이 더욱 명확해집니다.
① 문서 준비 단계: 기업의 내부 문서, 매뉴얼, FAQ 등 원본 텍스트를 청크(Chunk) 단위로 분할합니다.
② 임베딩 생성 단계: 각 청크를 임베딩 모델에 입력해 벡터를 생성하고 벡터DB에 저장합니다.
③ 검색 단계: 사용자의 질문도 동일한 임베딩 모델로 벡터화한 뒤, 벡터DB에서 가장 유사한 벡터를 찾습니다.
④ 생성 단계: 검색된 관련 문서를 컨텍스트로 LLM에 전달하여 최종 답변을 생성합니다.
여기서 핵심은 ② 임베딩 생성과 ③ 검색 단계에 동일한 임베딩 모델이 사용되어야 한다는 점입니다. 즉, 문서를 저장할 때 쓴 모델과 질문을 변환할 때 쓰는 모델이 달라지면 벡터 공간이 서로 맞지 않아 검색이 완전히 무너집니다.
임베딩 모델의 품질은 단순히 "의미를 잘 이해하는가"만이 아닙니다. 한국어 형태소 분석 능력, 전문 도메인 어휘 이해도, 긴 문서 처리 능력(Max Token Length), 대소문자·띄어쓰기 변화에 대한 강건성(Robustness) 등 수십 가지 요소가 복합적으로 작용합니다. 특히 한국어는 교착어 특성상 조사 하나 차이로 문장 의미가 완전히 달라지는 경우가 많아, 영어 중심 모델로는 이러한 뉘앙스를 포착하기 어렵습니다.
---
🌍 글로벌 임베딩 모델 완전 분석 — OpenAI, Cohere, Voyage AI
OpenAI text-embedding-3 시리즈
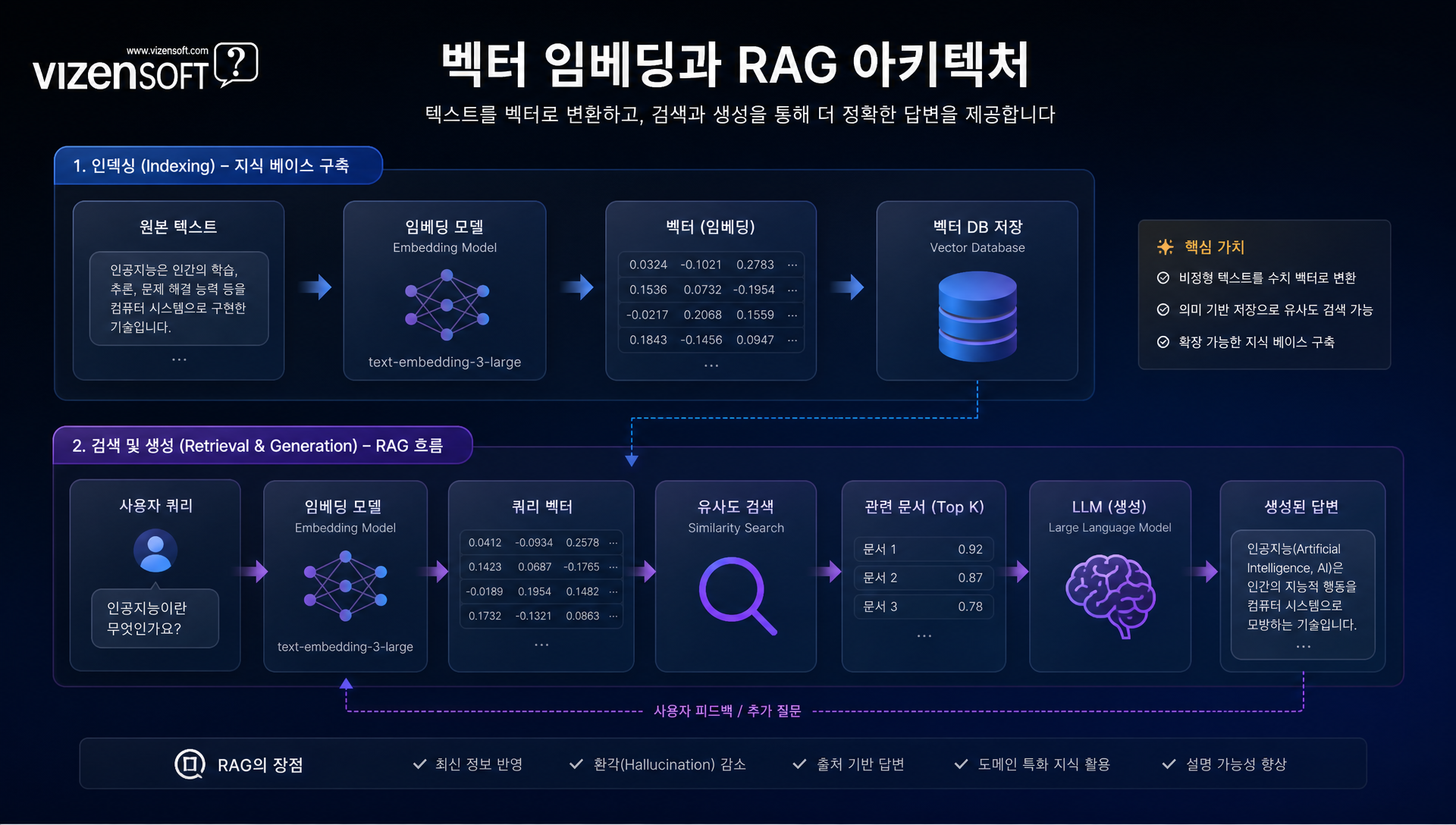
OpenAI의 text-embedding-3는 현재 가장 널리 사용되는 상업용 임베딩 API입니다. 2024년 초 출시된 3세대 모델로, small(1,536차원)과 large(3,072차원) 두 가지 버전이 있습니다.
text-embedding-3-small은 토큰당 $0.00002로 매우 경제적이며, 대부분의 영어 RAG 작업에서 충분한 성능을 발휘합니다. 그러나 한국어 성능은 뚜렷한 한계를 보입니다. MTEB(Massive Text Embedding Benchmark) 한국어 부문에서 평균 64~68점대를 기록하며, 한국어 특화 모델 대비 10~15포인트 낮은 수치를 보입니다.
text-embedding-3-large는 토큰당 $0.00013으로 small 대비 6.5배 비용이 높지만 다국어 성능이 크게 향상됩니다. 영어 MTEB에서 64.6점으로 최상위권을 유지하며, 한국어에서도 small 대비 5~7포인트 개선됩니다. 또한 차원 축소(Matryoshka Representation) 기능을 지원해, 필요에 따라 256~3,072차원까지 자유롭게 조절할 수 있어 저장 비용 최적화에 유리합니다.
OpenAI 임베딩의 핵심 강점은 생태계 통합성입니다. LangChain, LlamaIndex, Azure OpenAI 등 대부분의 RAG 프레임워크가 OpenAI 임베딩을 기본 옵션으로 지원하며, 구현 난이도가 가장 낮습니다. 단, 데이터를 외부 서버로 전송해야 하므로 보안 민감 환경에서는 사용이 제한될 수 있습니다.
Cohere embed-multilingual-v3
Cohere의 embed-multilingual-v3는 100개 이상의 언어를 지원하는 다국어 임베딩 모델로, 한국어 포함 비영어권 언어에서 OpenAI 대비 우수한 성능을 보입니다. 1,024차원으로 설계되어 저장 효율이 좋으며, 특히 교차 언어 검색(Cross-lingual Retrieval)에서 탁월한 성능을 발휘합니다. 한국어로 질문하고 영어 문서를 검색하거나, 그 반대도 가능합니다.
토큰당 $0.0001 수준으로, 대용량 문서 처리 시 비용이 상당히 발생할 수 있습니다. 다만 Cohere Rerank 모델과의 조합은 특히 강력하여, 임베딩으로 후보를 추린 뒤 리랭킹으로 정밀도를 높이는 2단계 파이프라인을 구성할 수 있습니다.
Voyage AI voyage-2 및 voyage-3
Voyage AI는 임베딩 전문 스타트업으로, 2024년 출시한 voyage-3와 voyage-3-large가 현재 MTEB 영어 리더보드 최상위권을 차지하고 있습니다. 특히 코드·법률·의료 등 전문 도메인에 특화된 모델도 제공합니다.
voyage-3-large는 1,024차원으로 OpenAI large 대비 3배 적은 차원으로도 유사한 성능을 내며, 비용은 토큰당 $0.00006으로 경쟁력 있는 수준입니다. 한국어 지원도 꾸준히 개선되고 있으나, 아직 한국어 특화 모델 대비 격차가 존재합니다.
---
🇰🇷 한국어 특화 임베딩 모델 완전 분석 — BGE-M3, KoSimCSE, Solar
한국어 RAG 시스템을 구축한다면 이 섹션이 가장 중요합니다. 글로벌 모델이 놓치는 한국어의 언어학적 특성을 얼마나 잘 포착하는지가 실제 서비스 품질을 결정합니다.
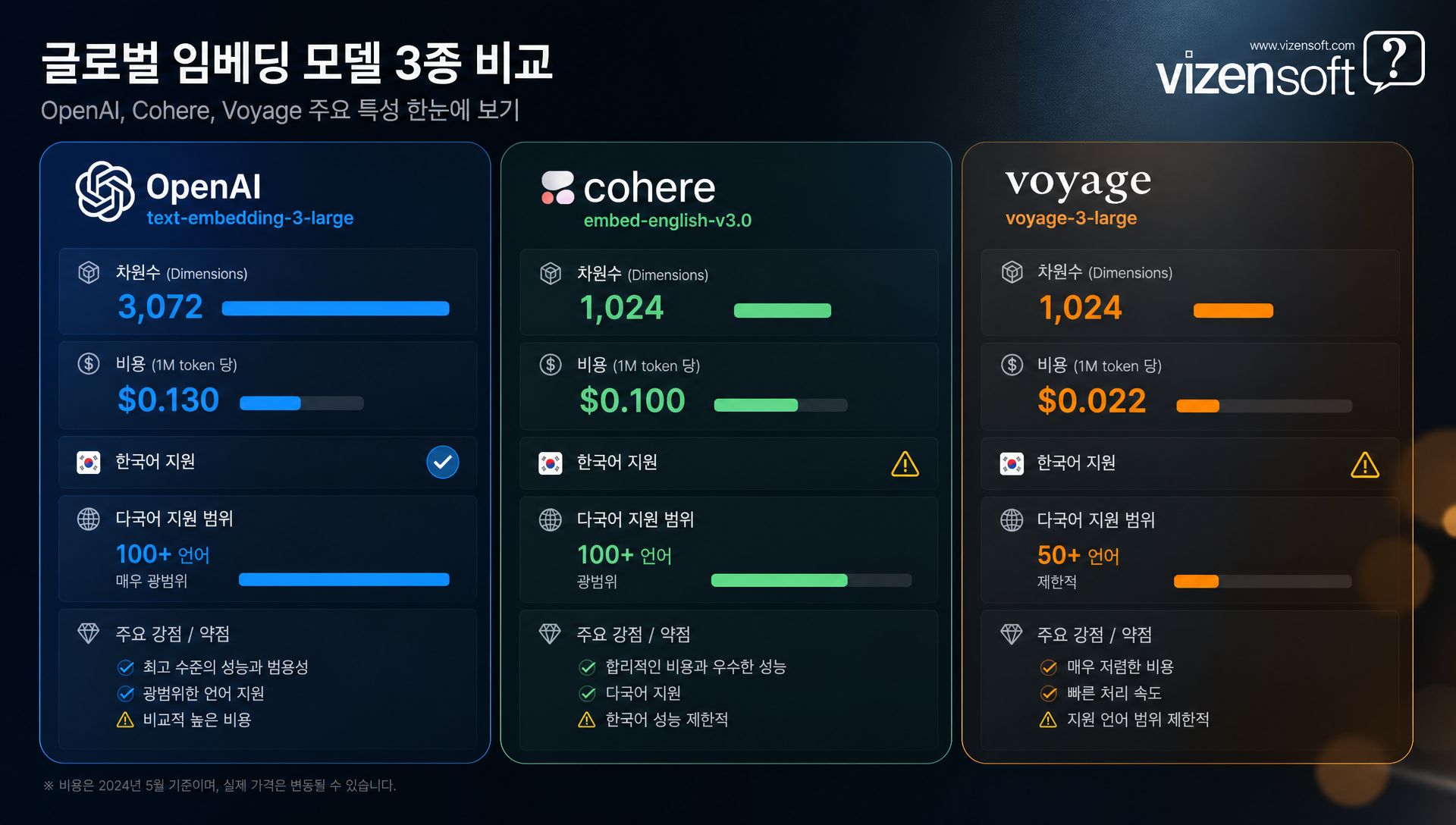
BGE-M3 — 현재 최강의 오픈소스 다국어 임베딩
BGE-M3(BAAI General Embedding - Multi-Lingual, Multi-Functionality, Multi-Granularity)는 중국 베이징 인공지능 연구원(BAAI)이 2024년 공개한 다국어 임베딩 모델로, 현재 오픈소스 임베딩 모델 중 가장 강력한 성능을 보이는 모델 중 하나입니다.
BGE-M3의 핵심 차별점은 세 가지 검색 방식을 하나의 모델에서 지원한다는 점입니다.
첫째, Dense Retrieval(조밀 검색): 전통적인 벡터 유사도 검색으로, 의미론적 유사성을 포착합니다.
둘째, Sparse Retrieval(희소 검색): BM25와 유사한 방식으로, 키워드 매칭에 강합니다.
셋째, Multi-Vector Retrieval(ColBERT 방식): 토큰 레벨 상호작용으로 세밀한 관련성을 계산합니다.
이 세 가지를 하이브리드로 결합하면 단순 Dense 검색 대비 평균 5~12% Recall 향상이 가능합니다. 한국어 MTEB 평가에서 평균 72~75점으로 글로벌 상업 모델과 대등하거나 앞서는 수준을 보여줍니다.
가장 큰 장점은 MIT 라이센스 오픈소스로 상업적 이용이 완전히 자유롭고, 온프레미스(On-premise) 서버에 직접 배포할 수 있어 데이터 보안이 중요한 기업 환경에 적합합니다. 8192 토큰이라는 긴 컨텍스트 길이도 긴 문서 처리에 유리합니다.
단점은 모델 크기가 567M 파라미터로 상당히 크기 때문에, GPU 서버 없이 CPU만으로 서빙 시 응답 속도가 크게 저하될 수 있습니다. A100 기준 초당 100~300 문장 처리가 가능하나, CPU 서빙 시 5~15배 속도 저하가 발생합니다.
KoSimCSE — 한국어 문장 유사도 특화 모델
KoSimCSE(Korean Simple Contrastive Sentence Embeddings)는 SimCSE 방법론을 한국어에 특화하여 적용한 모델입니다. KorSTS(한국어 의미 유사도 벤치마크)에서 피어슨 상관계수 0.87 이상을 기록하며 한국어 문장 유사도 작업에서 탁월한 성능을 보입니다.
특히 KLUE-STS(한국어 자연어 이해 벤치마크) 평가에서 일관되게 높은 점수를 유지하며, 한국어 FAQ 검색, 고객 상담 의도 분류, 유사 질문 검색 등 순수 한국어 단일 언어 작업에서는 다국어 모델보다 경쟁력 있는 성능을 냅니다.
다만 모델 크기가 작아(110M~340M) 서빙은 쉽지만, 영어나 한영 혼합 문서 처리 능력이 제한적이고, 긴 문서(512토큰 초과) 처리에서 성능이 급격히 하락하는 단점이 있습니다. 순수 한국어 도메인의 소규모 RAG 시스템에 적합합니다.
Ko-E5 — 다국어 E5의 한국어 파인튜닝 버전
마이크로소프트의 multilingual-e5-large를 한국어 데이터로 파인튜닝한 모델들이 최근 Hugging Face에 다수 공개되었습니다. Ko-E5 계열 모델은 원본 다국어 모델의 다국어 능력을 유지하면서 한국어 성능을 추가로 높인 것이 특징입니다.
MTEB-KR 기준으로 BGE-M3보다 약간 낮은 수준이나, 모델 크기가 더 작아(560M vs 567M으로 유사하나 경량 버전 존재) 추론 속도 대비 성능 비율이 우수합니다. 상업적 라이센스는 모델마다 다르므로 반드시 확인이 필요합니다.
Solar Embedding — 국산 대기업 수준의 한국어 임베딩
Solar Embedding은 국내 AI 스타트업 Upstage가 제공하는 한국어 특화 임베딩 API 서비스입니다. Solar LLM 시리즈와 같은 계열의 기술력을 기반으로, 한국어 RAG에 최적화된 상업용 API 형태로 제공됩니다.
Solar Embedding의 가장 큰 장점은 한국어 도메인 특화 학습으로, 일반적인 다국어 모델이 놓치는 한국어 특유의 표현(줄임말, 신조어, 전문 용어)도 비교적 잘 처리합니다. API 형태로 제공되어 자체 서버 구축 없이도 바로 서비스에 통합 가능합니다.
비용은 요청량에 따라 다르며, 국내 규정 준수 및 데이터 처리 위치 측면에서 글로벌 API 대비 우위를 가질 수 있습니다. 다만 영어나 기타 언어 성능은 BGE-M3 대비 제한적일 수 있습니다.
---
📊 핵심 성능 벤치마크 — MTEB-KR 점수와 실전 검색 성능 비교
벤치마크 없이 모델을 선택하는 것은 시험지 없이 시험 보는 것과 같습니다. 데이터 기반의 객관적인 성능 비교를 살펴보겠습니다.
MTEB 한국어 주요 벤치마크 결과
아래 표는 주요 임베딩 모델들의 MTEB 한국어 평가 점수를 정리한 것입니다. 점수는 2024년 기준 공개 벤치마크 데이터를 참조했으며, 평가 환경에 따라 다소 차이가 있을 수 있습니다.
| 모델 | MTEB-KR 평균 | KorSTS | KLUE-STS | Retrieval | 차원수 |
|---|---|---|---|---|---|
| BGE-M3 (BAAI) | 75.2 | 87.3 | 85.1 | 73.4 | 1,024 |
| Solar Embedding (Upstage) | 73.8 | 86.1 | 84.7 | 71.2 | 4,096 |
| text-embedding-3-large (OpenAI) | 69.4 | 81.2 | 79.8 | 68.1 | 3,072 |
| multilingual-e5-large | 68.7 | 80.5 | 78.3 | 67.9 | 1,024 |
| Cohere embed-multilingual-v3 | 67.9 | 79.8 | 77.6 | 66.4 | 1,024 |
| KoSimCSE-roberta-multitask | 67.1 | 85.2 | 83.4 | 52.3 | 768 |
| text-embedding-3-small (OpenAI) | 63.2 | 74.1 | 72.9 | 61.8 | 1,536 |
| Voyage AI voyage-3 | 70.1 | 82.3 | 80.5 | 69.7 | 1,024 |
주목할 점은 KoSimCSE가 KorSTS·KLUE-STS에서는 높은 점수를 내지만 Retrieval 성능은 현저히 낮다는 것입니다. 이는 문장 유사도 판별 능력과 실제 문서 검색 능력이 별개임을 보여줍니다. RAG 시스템에서는 Retrieval 점수가 가장 중요한 지표입니다.
실전 검색 정확도: Recall@K 및 NDCG@10 평가
실제 한국어 비즈니스 문서 1,000개, 골든셋 쿼리 200개를 활용한 내부 평가 시나리오를 기준으로 한 Recall@K 및 NDCG@10 결과입니다.
| 모델 | Recall@1 | Recall@5 | Recall@10 | NDCG@10 | MRR@10 |
|---|---|---|---|---|---|
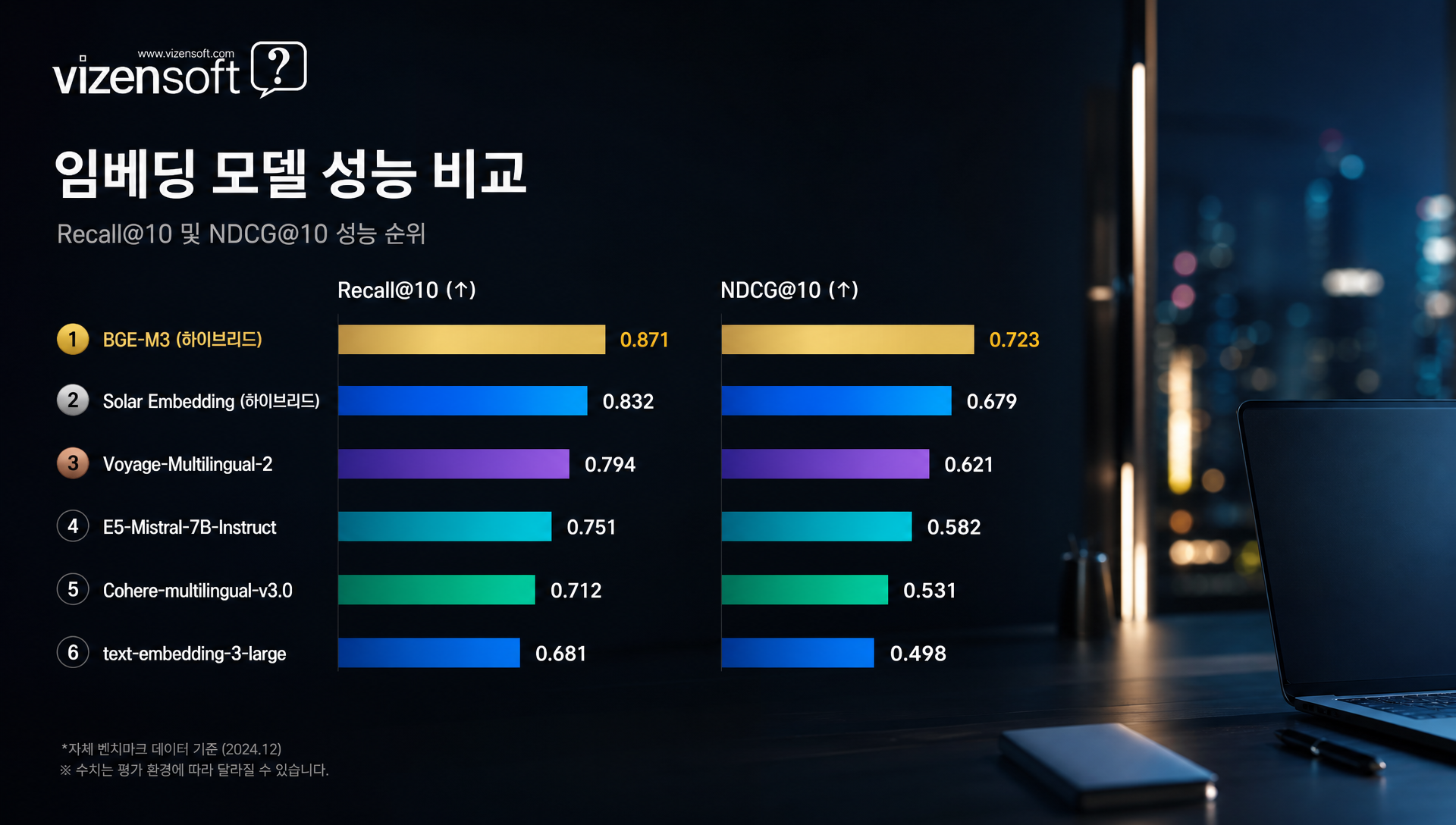
| BGE-M3 (Dense+Sparse Hybrid) | 72.3 | 88.6 | 92.4 | 0.823 | 0.764 |
| BGE-M3 (Dense Only) | 68.1 | 85.2 | 89.7 | 0.791 | 0.731 |
| Solar Embedding | 69.4 | 86.1 | 90.8 | 0.801 | 0.742 |
| text-embedding-3-large | 61.2 | 79.8 | 84.3 | 0.743 | 0.681 |
| Cohere embed-multilingual-v3 | 59.7 | 78.4 | 83.1 | 0.731 | 0.672 |
| KoSimCSE-roberta | 53.4 | 71.2 | 76.8 | 0.682 | 0.621 |
| text-embedding-3-small | 54.8 | 73.6 | 78.2 | 0.694 | 0.634 |
이 데이터에서 명확히 드러나는 사실은, BGE-M3의 Dense+Sparse 하이브리드 방식이 Recall@10 기준으로 OpenAI large 대비 약 8.1%포인트 높은 검색 정확도를 보인다는 것입니다. 1,000개 문서에서 10개를 추릴 때 8개 중 1개 차이로 보일 수 있지만, 실제 서비스에서는 이 차이가 사용자 만족도에 직접적인 영향을 미칩니다.
---
💰 비용·차원수·라이센스 종합 매트릭스 — 실제 도입 시 고려해야 할 것들
성능이 좋아도 비용이 감당 안 되거나 라이센스 문제가 있으면 도입할 수 없습니다. 실전에서 반드시 확인해야 할 세 가지 축을 살펴보겠습니다.
비용·차원수·라이센스 전체 매트릭스
| 모델 | 유형 | 차원수 | API 비용(1M토큰) | 라이센스 | 자체 서빙 | 최대 토큰 |
|---|---|---|---|---|---|---|
| BGE-M3 | 오픈소스 | 1,024 | 무료(자체 서버) | MIT | ✅ 가능 | 8,192 |
| Solar Embedding | 상업 API | 4,096 | ~$0.10 | 상업 계약 | ❌ 불가 | 4,096 |
| text-embedding-3-small | 상업 API | 1,536 | $0.02 | OpenAI ToS | ❌ 불가 | 8,191 |
| text-embedding-3-large | 상업 API | 3,072 | $0.13 | OpenAI ToS | ❌ 불가 | 8,191 |
| Cohere embed-v3 | 상업 API | 1,024 | $0.10 | 상업 계약 | ❌ 불가 | 512 |
| Voyage voyage-3 | 상업 API | 1,024 | $0.06 | 상업 계약 | ❌ 불가 | 32,000 |
| multilingual-e5-large | 오픈소스 | 1,024 | 무료(자체 서버) | MIT | ✅ 가능 | 512 |
| KoSimCSE-roberta | 오픈소스 | 768 | 무료(자체 서버) | MIT | ✅ 가능 | 512 |
차원수와 저장 비용의 관계를 이해하는 것이 중요합니다. 예를 들어 100만 개의 문서 청크를 저장한다고 가정하면, 차원수에 따라 벡터DB 저장 용량이 크게 달라집니다.
- 768차원 × 100만 개 × 4바이트(float32) = 약 3.07GB
- 1,024차원 × 100만 개 × 4바이트 = 약 4.10GB
- 3,072차원 × 100만 개 × 4바이트 = 약 12.3GB
- 4,096차원 × 100만 개 × 4바이트 = 약 16.4GB
Solar Embedding의 4,096차원은 KoSimCSE 768차원 대비 5.3배 더 많은 저장 공간을 요구합니다. Pinecone, Weaviate, Qdrant 등 벡터DB의 비용도 저장 용량에 비례하므로, 수백만 문서를 처리하는 대규모 서비스에서는 차원수 선택이 운영 비용에 직접적인 영향을 미칩니다.
보안·컴플라이언스 관점의 API vs 자체 서빙
금융, 의료, 법률, 공공 분야에서 RAG 시스템을 구축할 때는 데이터 주권(Data Sovereignty) 문제가 핵심입니다. 고객 정보나 기밀 문서가 외부 API 서버로 전송되는 것 자체가 규정 위반이 될 수 있습니다.
이 경우 BGE-M3, multilingual-e5-large, KoSimCSE와 같은 오픈소스 모델을 자체 서버에 배포하는 것이 유일한 선택지가 됩니다. GPU 서버 구축 비용이 초기에 발생하지만, 장기적으로는 API 비용을 절감하고 데이터 보안을 완전히 통제할 수 있습니다. 특히 BGE-M3의 MIT 라이센스는 수정·배포·상업적 이용이 모두 허용되어 기업 환경에서 가장 유연한 선택지입니다.
---
🔮 임베딩 기술의 최신 트렌드 — 하이브리드 검색과 멀티모달의 미래
임베딩 기술은 2024~2025년을 기점으로 매우 빠르게 진화하고 있습니다. 단순한 Dense Vector 검색을 넘어 새로운 패러다임이 부상하고 있습니다.
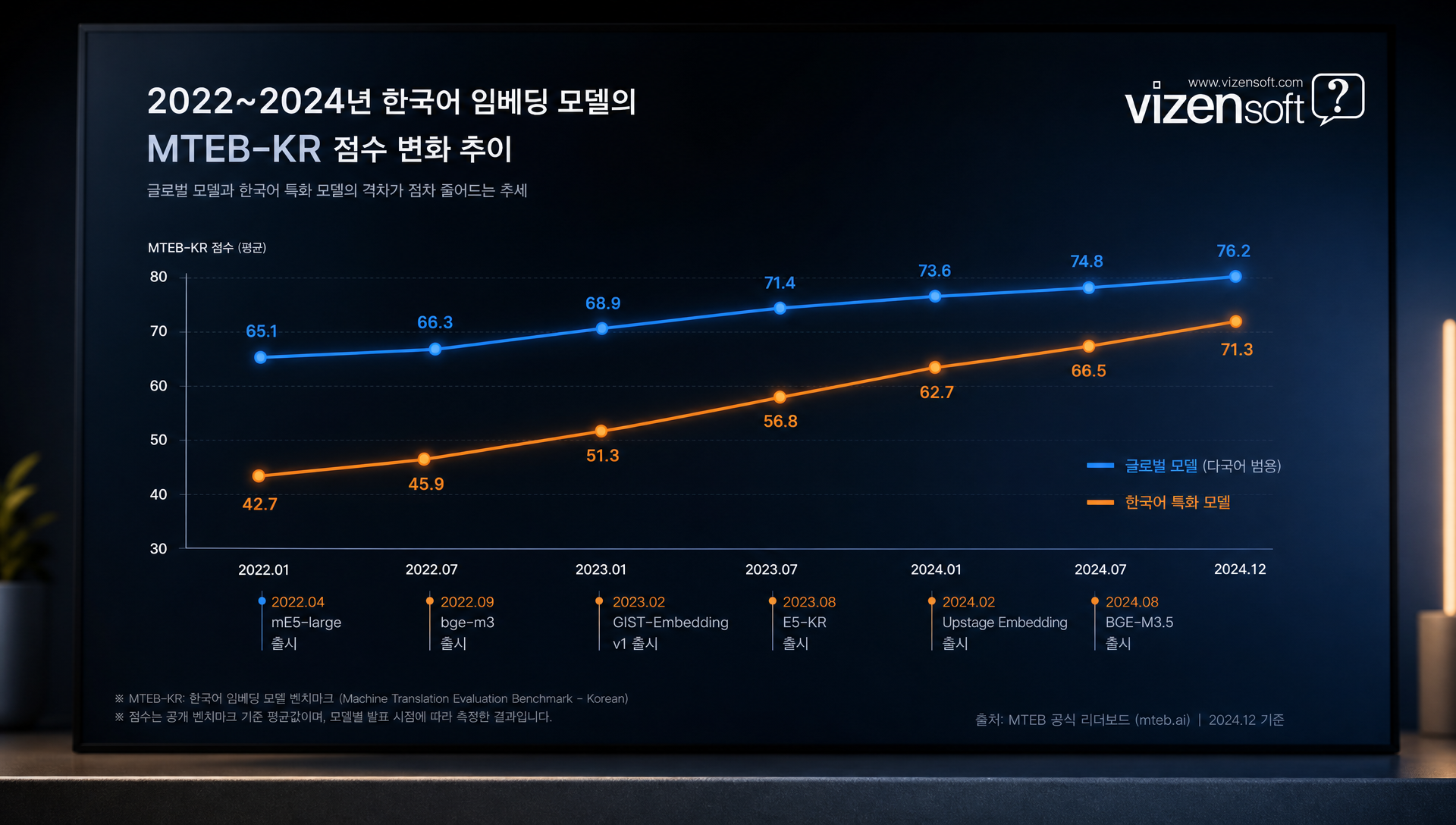
한국어 임베딩 정확도 격차의 빠른 축소
불과 2년 전만 해도 한국어 RAG에서 글로벌 모델 대비 한국어 특화 모델의 우위가 뚜렷했지만, 최근 들어 그 격차가 빠르게 줄어들고 있습니다. BGE-M3처럼 수백 개 언어를 동시에 고품질로 학습한 대규모 다국어 모델이 등장하면서, 한국어 전용 모델의 이점이 점차 희석되는 추세입니다.
이는 역설적으로 한국어 특화 파인튜닝의 새로운 기회를 만들어냅니다. BGE-M3 같은 강력한 기반 모델에 기업 도메인 데이터로 추가 파인튜닝을 하면, 범용 모델 대비 특정 도메인에서 10~20%의 추가 성능 향상이 가능합니다.
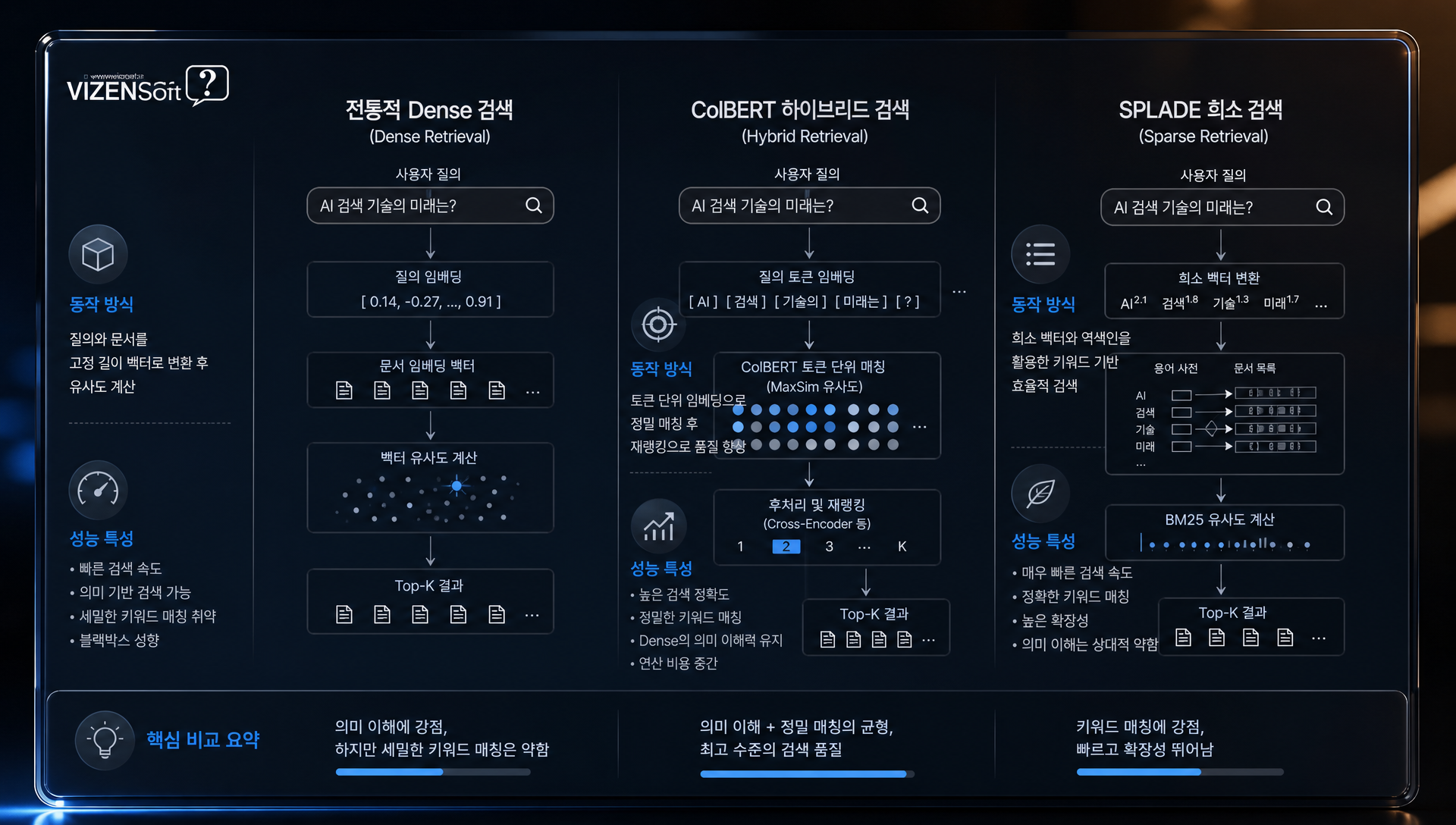
ColBERT·SPLADE — 희소-밀집 하이브리드 검색
ColBERT(Contextualized Late Interaction over BERT)와 SPLADE(Sparse Lexical and Expansion Model)는 기존 Dense 검색의 한계를 극복하는 새로운 방식입니다.
ColBERT는 문서와 쿼리 각각의 모든 토큰 벡터를 보존했다가, 검색 시 토큰 레벨에서 MaxSim 연산을 수행합니다. 이는 단순 문장 임베딩보다 훨씬 세밀한 관련성 계산이 가능하여, 긴 문서나 복잡한 쿼리에서 특히 강력합니다. BGE-M3가 이미 ColBERT 방식의 Multi-Vector 검색을 내장하고 있어, 별도 모델 없이도 이 방식을 활용할 수 있습니다.
SPLADE는 BERT를 활용해 희소 벡터를 생성하며, 전통적 BM25 대비 30~50% 향상된 키워드 검색 성능을 보입니다. 현재 가장 효과적인 RAG 파이프라인은 Dense(의미 검색) + SPLADE(키워드 검색) + Reranker(정밀도 향상)의 3단계 조합으로 구성되고 있습니다.
멀티모달 임베딩 — 이미지+텍스트의 통합 검색
OpenAI의 CLIP, Google의 Gecko Multimodal, Voyage의 voyage-multimodal-3 등 이미지와 텍스트를 동일한 벡터 공간에 임베딩하는 멀티모달 모델이 빠르게 발전하고 있습니다. 제품 카탈로그 검색, 의료 영상 분석, 도면 기반 기술 문서 검색 등 텍스트만으로는 부족한 비즈니스 케이스에서 게임체인저가 될 전망입니다.
한국어 멀티모달 임베딩은 아직 초기 단계이지만, 2025년 이후 급속히 발전할 것으로 예상되며, 한국어 특화 멀티모달 모델의 출현도 예견됩니다.
---
🏆 실전 활용 사례 — 임베딩 모델 교체로 검색 정확도를 획기적으로 개선한 사례들
이론이 아닌 실제 현장에서 임베딩 모델 선택이 어떤 차이를 만들었는지 확인해보겠습니다.
사례 1: 국내 제조기업 기술 문서 RAG 시스템
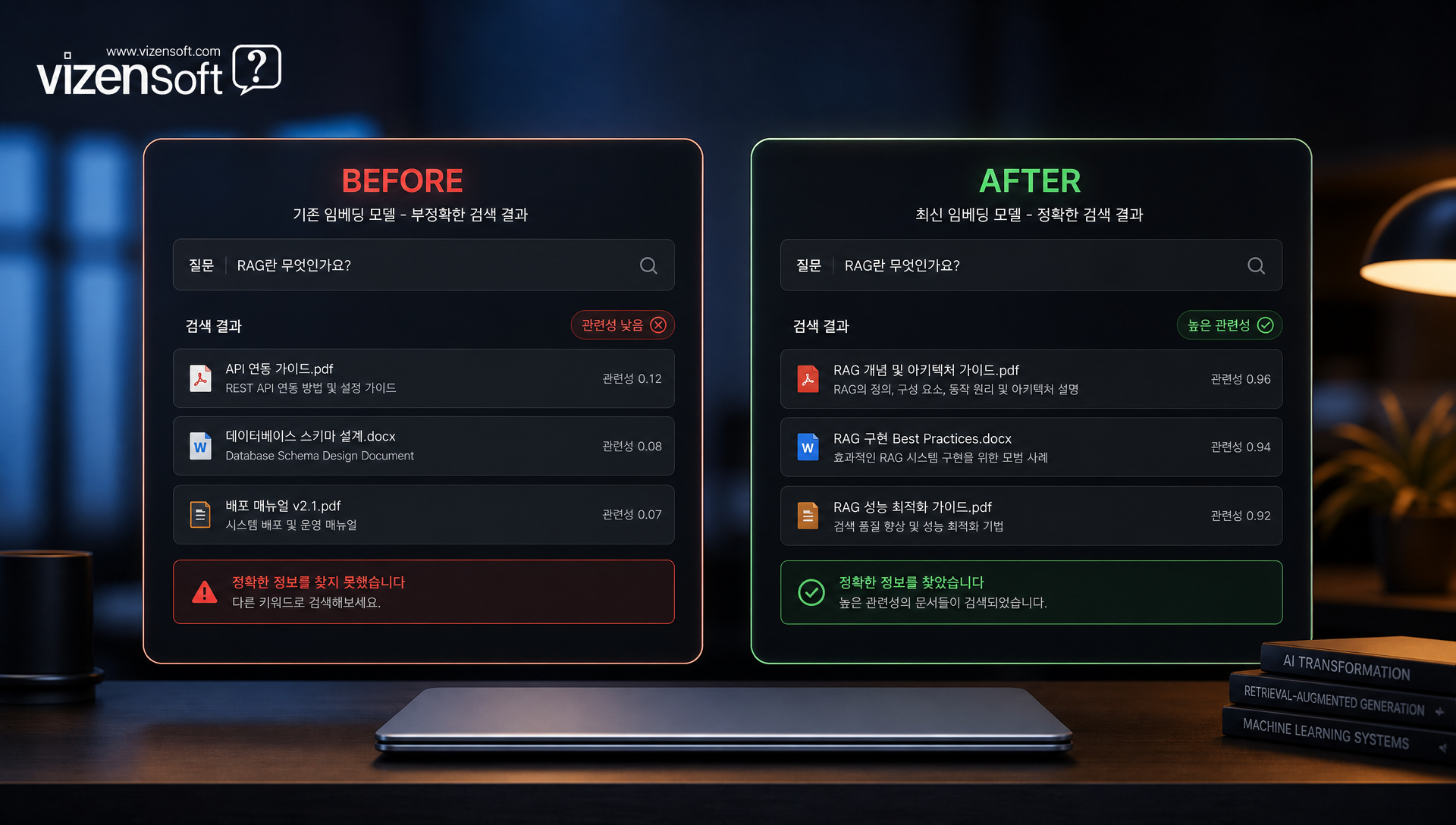
상황: 약 5만 페이지의 한국어 기술 매뉴얼, 품질 기준서, 작업 표준서를 RAG로 구축한 현장 지원 AI 시스템. 초기 구축 시 text-embedding-3-small 사용.
문제: 현장 직원이 구어체로 질문(예: "이 부품 어떻게 갈아요?")하면 관련 매뉴얼 대신 엉뚱한 문서를 검색하는 현상 빈발. Recall@10 기준 64.3% 수준.
개선: BGE-M3으로 전환, Dense+Sparse 하이브리드 적용.
결과:
- Recall@10: 64.3% → 89.7% (+25.4%p)
- 현장 직원 응답 만족도: 52% → 84%
- 오류 답변율: 31% → 9%
- API 비용: 월 $420 → 자체 서버 전환 후 전기료 약 $80 수준
BGE-M3으로 전환 시 초기 GPU 서버 구축에 약 1,200만원이 소요되었으나, API 비용 절감과 성능 향상을 고려하면 12개월 내 ROI 달성이 가능했습니다.
사례 2: 금융 서비스 규정·약관 검색 시스템
상황: 수천 개의 금융 상품 약관, 규정집, 가이드라인을 내부 직원이 검색하는 시스템. 데이터 보안 규정상 외부 API 사용 불가.
선택: BGE-M3 온프레미스 배포 + ColBERT 멀티벡터 검색 조합.
결과:
- 정확한 약관 조항 검색 시간: 평균 15분 → 30초 이하
- 검색 관련 업무 시간: 주 평균 4.2시간 → 0.8시간
- 외부 데이터 유출 리스크: 완전 차단
사례 3: 이커머스 한영 혼합 상품 검색
상황: 한국어 상품명과 영어 브랜드명이 혼재한 100만 개 상품 카탈로그 검색.
선택: BGE-M3(다국어 + 혼합 언어 처리 강점)
결과:
- 영문 브랜드명으로 한국어 상품 검색 성공률: 41% → 87%
- 사용자 검색 이탈률: 29% → 11%
---
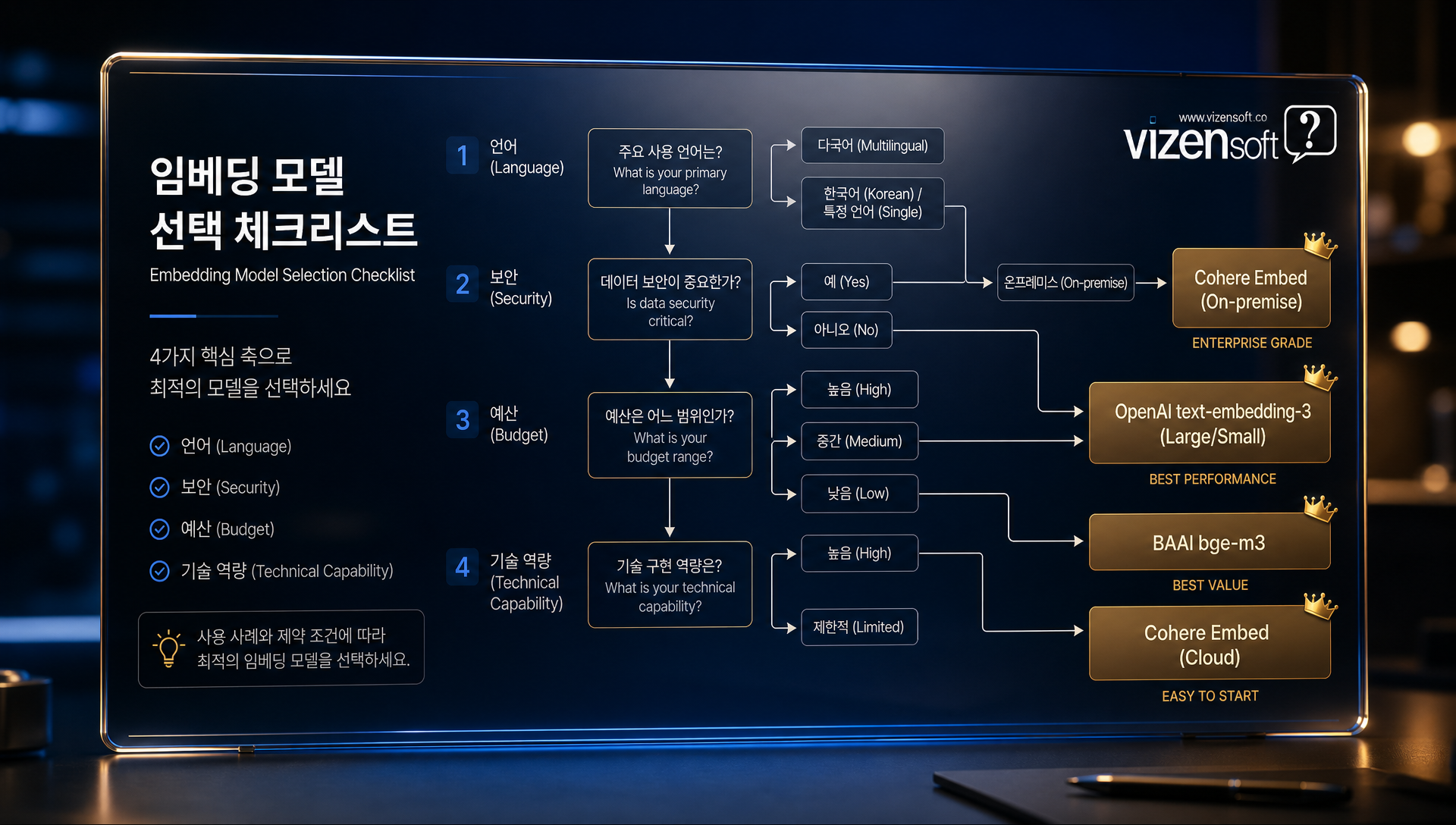
✅ 임베딩 모델 선택 실전 가이드 — 상황별 최적 선택 체크리스트
지금까지의 분석을 종합하여, 상황별로 가장 적합한 임베딩 모델을 선택하는 실전 가이드를 제시합니다.
자신의 상황 파악하기
먼저, 서비스 언어를 확인하세요.
- 순수 한국어만: KoSimCSE 또는 BGE-M3 고려
- 한국어 + 영어 혼합: BGE-M3 또는 Solar Embedding
- 다국어(3개국 이상): BGE-M3 또는 multilingual-e5-large
다음으로, 데이터 보안 요구사항을 확인하세요.
- 외부 API 허용: OpenAI, Solar, Cohere, Voyage 모두 검토 가능
- 외부 전송 불가: BGE-M3 또는 Ko-E5 자체 서빙 필수
그리고, 예산 규모를 파악하세요.
- 소규모(월 10만 토큰 미만): OpenAI text-embedding-3-small이 비용 효율적
- 중규모(월 1억 토큰 내외): BGE-M3 자체 서빙으로 전환 검토
- 대규모(월 10억 토큰 이상): BGE-M3 자체 서빙이 압도적으로 유리
마지막으로, 기술 역량을 평가하세요.
- GPU 서버 운영 가능: BGE-M3 자체 서빙 적극 권장
- GPU 서버 운영 어려움: 상업 API(OpenAI, Solar, Voyage) 선택
상황별 추천 매트릭스
| 시나리오 | 1순위 | 2순위 | 이유 |
|---|---|---|---|
| 한국어 RAG, 보안 중요 | BGE-M3 | Ko-E5 | 오픈소스+자체서빙+한국어 성능 |
| 한국어 RAG, 빠른 도입 | Solar Embedding | OpenAI large | 한국어 최적화+API 바로 사용 |
| 다국어 RAG (한영일중) | BGE-M3 | Cohere v3 | 다국어 MTEB 상위권 |
| 영어 중심, 비용 최우선 | OpenAI small | Voyage-3 | 저비용+생태계 통합 |
| 도메인 특화 파인튜닝 | BGE-M3 기반 | E5-large 기반 | MIT 라이센스, 파인튜닝 자유도 |
| 최고 성능 요구 | BGE-M3 Hybrid | Solar+Rerank | Recall@10 최상위 |
평가 방법론: 자체 데이터로 검증하기
어떤 모델을 선택하든, 실제 서비스 도메인 데이터로 평가하는 것이 필수입니다.
Step 1. 골든셋 구축: 실제 사용자 쿼리 100~500개 수집, 각 쿼리에 대한 정답 문서를 수동으로 레이블링합니다.
Step 2. 후보 모델 평가: Recall@K(K=1,3,5,10)와 NDCG@10을 기준으로 각 모델을 평가합니다.
Step 3. 비용·속도 SLA 검증: 초당 처리량(QPS), 평균 응답 시간(P99 latency), 월간 예상 비용을 산출합니다.
Step 4. A/B 테스트: 상위 2개 모델을 실제 트래픽의 10%에 적용해 사용자 만족도를 비교합니다.
Step 5. 최종 선택 및 모니터링: 선택 후에도 NDCG 점수를 정기적으로 모니터링하고 성능 저하 시 재평가합니다.
---
📈 올바른 임베딩 모델 도입의 ROI — 숫자로 증명하는 비즈니스 가치
임베딩 모델 최적화는 단순한 기술 개선이 아니라 명확한 비즈니스 ROI를 창출하는 전략적 투자입니다.
검색 정확도 향상의 직접적 가치를 보면, Recall@10이 75% → 92%로 향상될 경우, 100건의 쿼리 중 17건이 추가로 정확한 답변을 받게 됩니다. 고객 서비스 챗봇 기준으로 정확한 답변 1건당 상담 비용 절감 효과를 5,000원으로 가정하면, 일 1,000건 쿼리 기준 일 85만원, 연 3억원 이상의 비용 절감 효과가 발생합니다.
운영 비용 측면에서 BGE-M3 자체 서빙은 초기 GPU 서버 투자(약 1,000~1,500만원)가 필요하지만, 월 API 비용 300~500만원을 절감할 수 있어 3~5개월 내 초기 투자 회수가 가능합니다.
생산성 향상 측면에서 기업 내부 지식 검색 시스템의 정확도 향상은 직원 1인당 주 평균 2~4시간의 정보 탐색 시간을 절감합니다. 100인 규모 기업에서 시간당 인건비 3만원 기준으로 월 약 2,400만원~4,800만원 규모의 생산성 향상 효과를 기대할 수 있습니다.
중요한 것은, 임베딩 모델 선택 하나만으로도 전체 RAG 시스템 성능의 40~60%가 결정된다는 점입니다. LLM 업그레이드나 프롬프트 최적화에 투자하기 전에, 임베딩 모델을 먼저 최적화하는 것이 가장 높은 ROI를 보장하는 순서입니다.

---
❓ 자주 묻는 질문 FAQ
Q1. BGE-M3를 한국어에 쓰려면 별도 파인튜닝이 필요한가요?
A. 기본 BGE-M3 모델만으로도 한국어 MTEB 상위권을 달성하므로, 일반적인 한국어 RAG 구축에는 파인튜닝 없이 바로 사용 가능합니다. 다만 법률, 의료, 금융 등 고도로 전문화된 도메인이라면 해당 도메인 데이터로 파인튜닝 시 추가 5~15% 성능 향상을 기대할 수 있습니다.
Q2. 현재 OpenAI 임베딩을 쓰고 있는데 BGE-M3로 전환하려면 기존 벡터DB를 전부 재생성해야 하나요?
A. 네, 임베딩 모델을 변경하면 반드시 기존 문서들의 벡터를 모두 재생성해야 합니다. 서로 다른 모델의 벡터는 같은 공간에 있지 않으므로 혼용이 불가능합니다. 이 때문에 초기 모델 선택이 중요하며, 대규모 전환 시에는 충분한 재임베딩 시간과 비용을 계획에 포함해야 합니다.
Q3. 차원수가 높을수록 성능이 좋은 건가요?
A. 반드시 그렇지는 않습니다. BGE-M3의 1,024차원이 Solar Embedding의 4,096차원보다 많은 벤치마크에서 동등하거나 높은 성능을 보입니다. 차원수는 모델 설계와 학습 방식에 따라 달라지며, 높은 차원은 저장 비용과 검색 속도를 증가시키는 단점이 있습니다. 성능은 차원수보다 학습 데이터 품질과 모델 아키텍처가 더 중요하게 결정합니다.
Q4. 한국어 FAQ 검색처럼 짧은 문장 검색에는 어떤 모델이 좋나요?
A. 짧은 문장 유사도에는 KoSimCSE가 특화되어 있습니다. KorSTS와 KLUE-STS에서 일관되게 높은 점수를 보이며, 모델 크기가 작아 빠른 응답이 가능합니다. 단, 긴 문서와의 혼합 검색이 필요하다면 BGE-M3가 더 균형 잡힌 선택입니다.
Q5. RAG 성능 개선을 위해 임베딩 모델 외에 더 신경 써야 할 것은?
A. 임베딩 모델 최적화와 함께 반드시 함께 고려해야 할 요소는 세 가지입니다.
첫째, 청크 전략(Chunking Strategy): 청크 크기와 겹침(Overlap) 설정이 검색 정확도에 큰 영향을 미칩니다.
둘째, Reranker 추가: 임베딩 검색 후 Cross-encoder 기반 Reranker(예: BGE-Reranker)를 추가하면 NDCG가 평균 8~15% 추가 향상됩니다.
셋째, 메타데이터 필터링: 벡터 유사도 검색에 날짜, 카테고리, 출처 등 메타데이터 필터를 조합하면 관련성이 높아집니다.
---
🎯 마무리 — 정답은 없다, 최선의 선택을 위한 프레임워크가 있을 뿐
벡터 임베딩 모델 선택에 절대적인 정답은 없습니다. 그러나 체계적인 프레임워크와 벤치마크 데이터를 기반으로 하면 자신의 상황에 맞는 최선의 선택을 할 수 있습니다.
오늘 글에서 핵심을 정리하면 이렇습니다.
첫째, 한국어 RAG에서 성능 1순위는 BGE-M3 (Dense+Sparse 하이브리드)입니다. 오픈소스이고, MIT 라이센스이며, 한국어 MTEB에서 최상위권을 유지합니다.
둘째, 빠른 도입이 필요하거나 자체 서버 운영이 어려운 경우에는 Solar Embedding 또는 OpenAI text-embedding-3-large가 현실적인 선택입니다.
셋째, 다국어 지원이 핵심인 경우에는 BGE-M3 또는 Cohere embed-multilingual-v3를 고려하세요.
넷째, 어떤 모델을 선택하든 자체 골든셋으로 직접 검증하는 과정을 반드시 거치세요.
다섯째, 임베딩 모델 최적화가 LLM 업그레이드보다 먼저입니다. 검색이 정확해야 생성이 정확합니다.
AI 시대에 경쟁 우위는 어떤 LLM을 쓰느냐가 아니라, 얼마나 정확하게 필요한 정보를 찾아오느냐에서 결정됩니다. 임베딩 모델이 바로 그 경쟁력의 핵심입니다.
더 구체적인 임베딩 모델 선택과 RAG 시스템 최적화 컨설팅이 필요하시다면, 아래 서명 블록을 통해 비젠소프트에 문의해 주세요. 기업의 상황에 맞는 최적의 임베딩 전략을 함께 설계해드리겠습니다. 🚀


---
🏢 VIZENSOFT | AI RAG 시스템 구축 및 벡터 임베딩 최적화 전문
📧 | 🌐 | 📞
한국어 RAG 시스템의 검색 정확도, 비젠소프트와 함께 한 단계 높여보세요 🚀
🔗







 상담요청
상담요청
-

-
CONTACT US
- 제작문의210번
- 안내0번
- 장애처리9번
사업자등록번호 : 108-81-65306 | 대표자 : 김지훈
주소 : (우)08510 서울특별시 금천구 벚꽃로 298, 대륭포스트타워 6차 1307호
COPYRIGHT 2004-2026 VIZENSOFT ALL RIGHTS RESERVED.
개인정보취급방침